MoE架构深度解析
原理、策略与未来展望
深入解析MoE (Mixture of Experts)架构原理、专家路由策略、动态调度与资源最优化机制;探讨量子加速、边缘协同等未来方向
引言
混合专家模型(Mixture of Experts, MoE)作为深度学习领域的一项创新性架构,近年来在大型语言模型(LLM)领域取得了瞩目的成就。MoE通过将模型参数分散到多个"专家"子网络中,并使用动态路由机制选择性地激活部分专家,实现了在保持高性能的同时显著提升计算效率的目标。
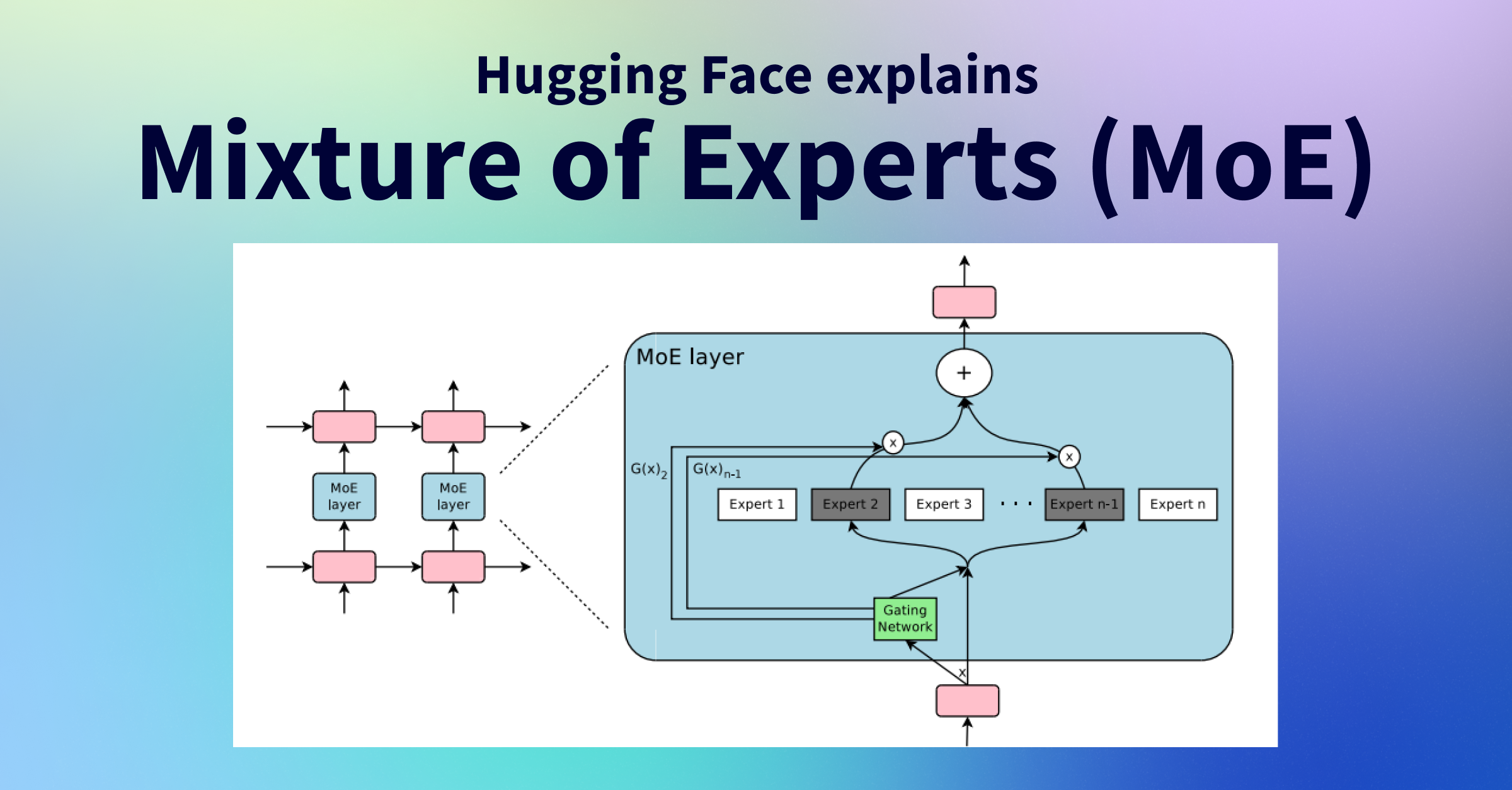
图1: MoE架构概览 (来源: Hugging Face)
随着大型语言模型规模不断扩大,传统的密集型模型架构面临计算资源与性能之间的权衡困境。MoE架构通过稀疏激活机制,为大规模模型训练和推理提供了一种高效解决方案。本文将深入探讨MoE的架构原理、专家路由策略、动态调度与资源优化机制,并展望量子加速、边缘计算协同等未来发展方向。
一、MoE架构基本原理
1.1 核心概念与结构
MoE架构的核心思想是将一个复杂的任务分解为多个子任务,由不同的"专家"网络分别处理,然后通过一个门控网络(Gating Network)动态决定激活哪些专家来处理当前输入。这种结构起源于20世纪90年代Jacobs等人的研究,但在大型语言模型时代获得了新的生命力。
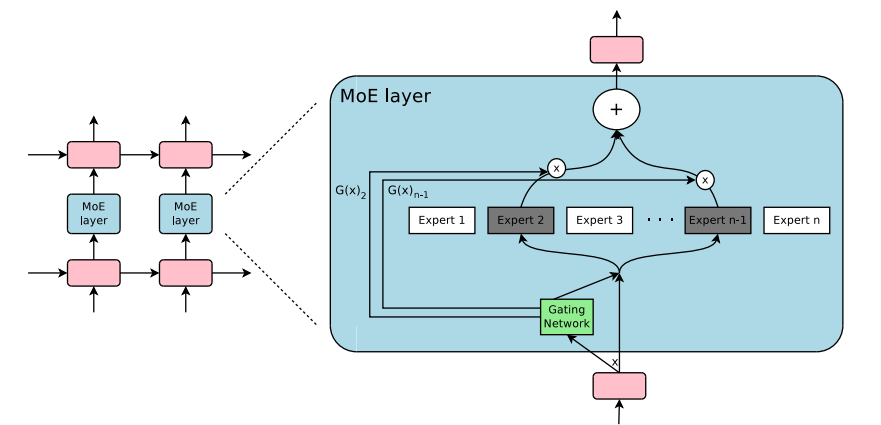
图2: MoE层的基本结构 (来源: Hugging Face)
MoE层的基本结构如上图所示,它主要由两个核心组件组成:
多个并行的神经网络,每个专家负责处理特定类型的输入。在Transformer架构中,专家通常是前馈网络(FFN)层。每个专家可以专注于学习特定的模式或语言特征。
决定输入应该由哪些专家处理,并为每个专家分配权重。门控网络通常使用Softmax函数计算专家选择概率,根据输入特征动态路由到最合适的专家。
1.2 MoE在Transformer中的应用
在现代Transformer架构中,MoE主要用于替换传统的前馈网络层(FFN)。相比于每个位置使用相同的FFN,MoE模型为每个输入令牌动态选择最适合的专家子网络,从而实现更高效的计算。
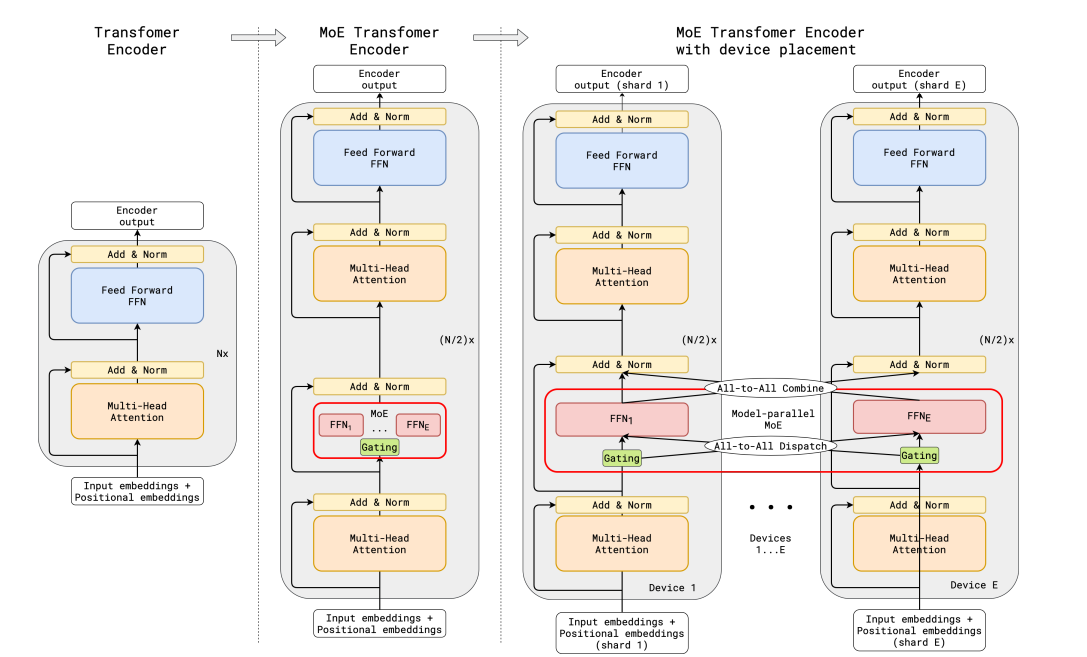
图3: MoE在Transformer中的应用 (来源: Hugging Face)
MoE的典型执行流程如下:
1. 输入令牌嵌入通过门控网络获取专家选择概率:
θ = Softmax(R(x))
其中x是输入令牌嵌入,R(·)是路由函数,θ表示N个专家的选择概率。
2. 选择Top-k专家(通常k=1或k=2):
E_selected = TopK(θ, K)
3. 被选中的专家并行处理输入:
y_i = E_i(x), ∀i ∈ E_selected
4. 基于门控权重组合专家输出:
y = ∑(θ_i/∑θ_j) · y_i, i ∈ E_selected
1.3 MoE模型的优势
通过只激活部分专家,大幅降低计算量,同时保持模型容量。这使得模型能够在有限的计算资源下处理更复杂的任务。
不同专家可以专注于不同类型的输入模式,提高处理效果。例如,某些专家可能专注于处理数学问题,而其他专家则擅长处理语言表达。
通过增加专家数量,模型容量可以线性增长,而计算复杂度增长较小。这使得MoE架构特别适合构建超大规模模型。
根据输入复杂度,可以动态调整计算资源分配。简单的输入可以仅使用少量专家,而复杂的输入则可以调用更多专家协同处理。
现实应用示例: 最新的MoE模型如Mixtral-8x7B和DeepSeek-MoE展示了稀疏激活的优势。Mixtral-8x7B在每个令牌处理过程中仅激活8个专家中的2个,但性能超过许多更大的密集模型。
二、专家路由策略深度分析
2.1 经典路由机制
早期的MoE模型主要采用固定Top-k路由策略,即对每个输入令牌,选择概率最高的k个专家(通常k=1或k=2)进行处理。这种方法简单有效,但也存在局限性,如负载不平衡和专家利用不充分等问题。
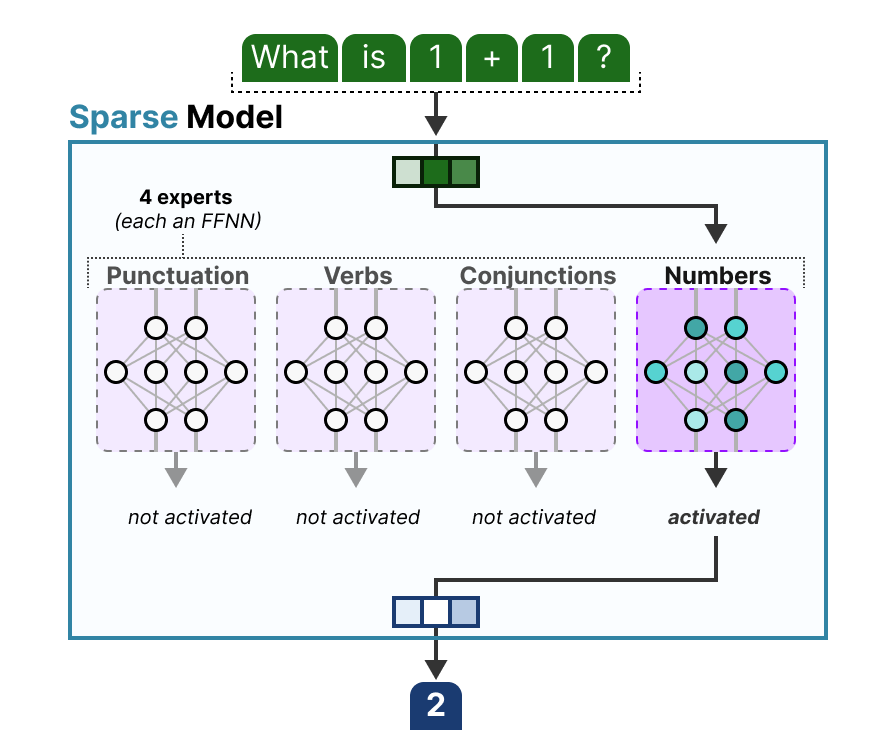
图4: 传统Top-k路由示意图 (来源: Exploring Language Models)
2.2 路由算法优化
为解决传统路由策略的问题,研究人员提出了多种改进方案:
2.2.1 负载均衡优化
负载均衡是MoE路由中的关键问题。如果某些专家频繁被激活而其他专家闲置,会导致计算资源浪费和性能下降。
Switch Transformers和GShard引入了辅助损失函数来促进负载均衡:
L_aux = α · CV(f)²
其中CV(f)是专家使用频率的变异系数,α是权衡因子。这一辅助损失鼓励门控网络更均匀地分配任务给所有专家。
2.2.2 动态自适应路由
动态路由策略根据输入复杂度和系统状态自适应地选择专家数量,进一步提高效率:
使用Fisher信息矩阵计算专家重要性,动态跳过不重要的专家,实现25%的计算量减少。
提出自上而下的门控方法,实现每个令牌灵活分配专家,根据计算需求动态确定专家数量。
采用基于阈值的动态专家激活策略,平衡计算效率和模型性能。
| 方法 | FLOPs减少 | 加速比 | 阈值策略 | 负载均衡 |
|---|---|---|---|---|
| 固定top-k | 0% | 1.0x | - | ✓ |
| Li等人 | 38.2% | 1.32x | 软阈值 | 仅top-1 |
| DynMoE | 9% | 1.37x | 单专家概率 | ✓ |
| XMoE | 75% | - | 累积概率 | ✓ |
| AdapMoE | 25% | 1.35x | 性能扰动 | ✗ |
2.2.3 Expert Choice Routing
与传统的"token-to-expert"路由(令牌选择专家)不同,Google研究提出了"expert-to-token"路由机制,让专家选择令牌。这种方法通过反转选择过程,能更好地控制每个专家的负载。
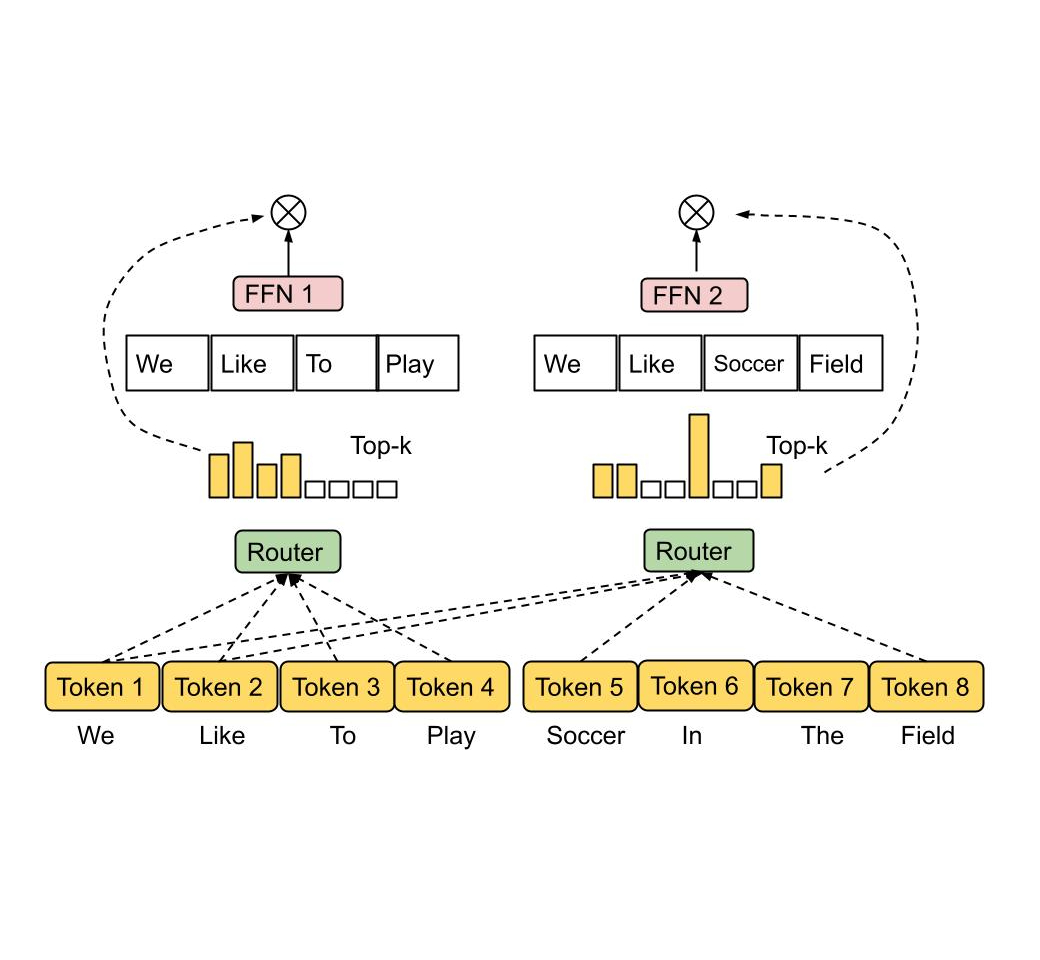
图5: Expert Choice Routing示意图 (来源: Google Research)
2.3 基于哈希的路由
HashLayer提出了一种基于哈希函数的确定性路由机制,无需训练门控网络,直接通过哈希函数将输入映射到专家。这种方法简化了实现,并有助于负载均衡,但可能缺乏输入相关的专业化能力。
研究趋势: 最新研究表明,混合路由策略(结合确定性和学习型路由)在实践中表现最佳,能同时保证负载均衡和专业化能力。
三、MoE模型资源优化技术
3.1 模型级优化
3.1.1 架构设计优化
研究者们不断探索更高效的MoE架构设计:
引入三种基于标准专家的零计算专家,减少计算开销。
提出预门控MoE模块,预先获取所需专家,提高内存受限设备上的推理速度。
引入基于树的稀疏专家选择机制,优化传统的线性门控模块。
一些创新性架构还将MoE应用于注意力机制:
将多头注意力机制视为MoE系统,使用学习的门控函数为不同输入激活不同专家。
将稀疏模块扩展到注意力和前馈层,方便模块的添加和移除。
开发结合稀疏注意力和稀疏前馈层的高效模型。
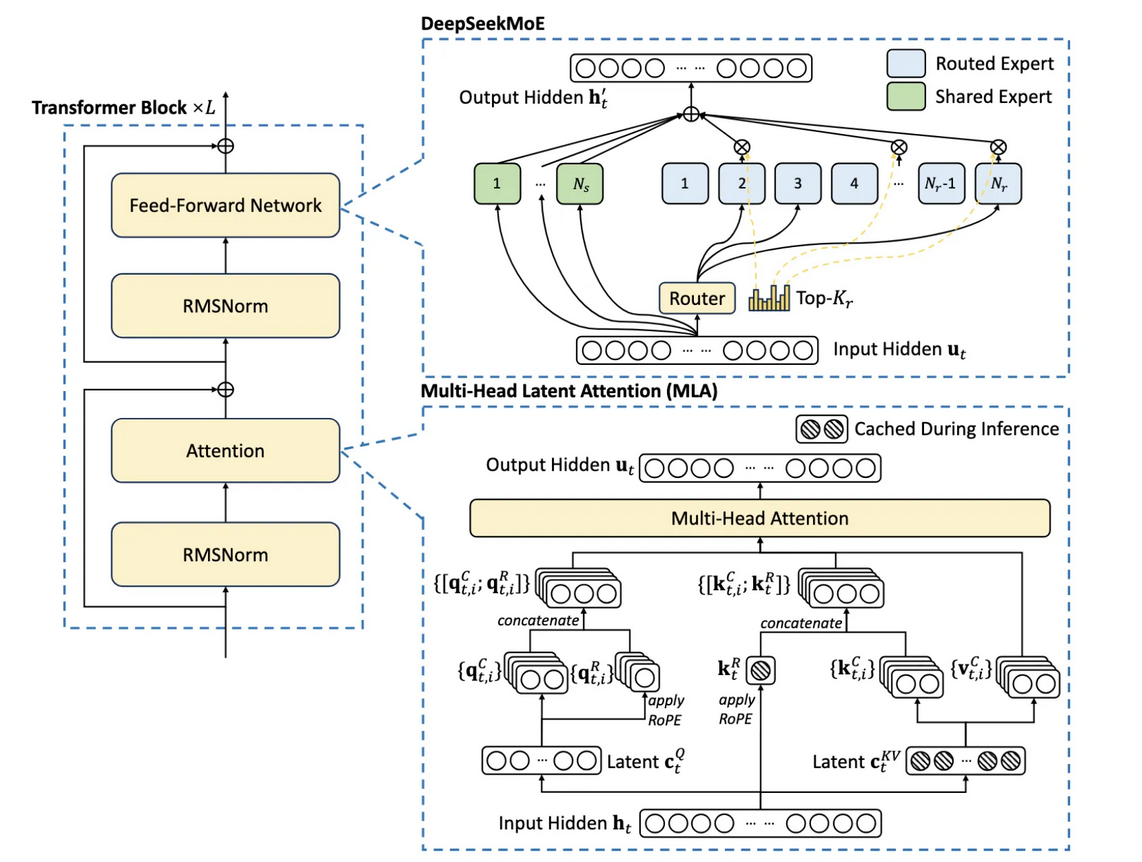
图6: DeepSeek MoE架构示例 (来源: Level Up Coding)
3.1.2 模型压缩技术
MoE模型的规模庞大,压缩技术至关重要:
专家剪枝
TSEP、NAEE、UNCURL等方法直接移除不重要的专家,而EEP、HC-SMoE等则通过参数合并减少专家数量。
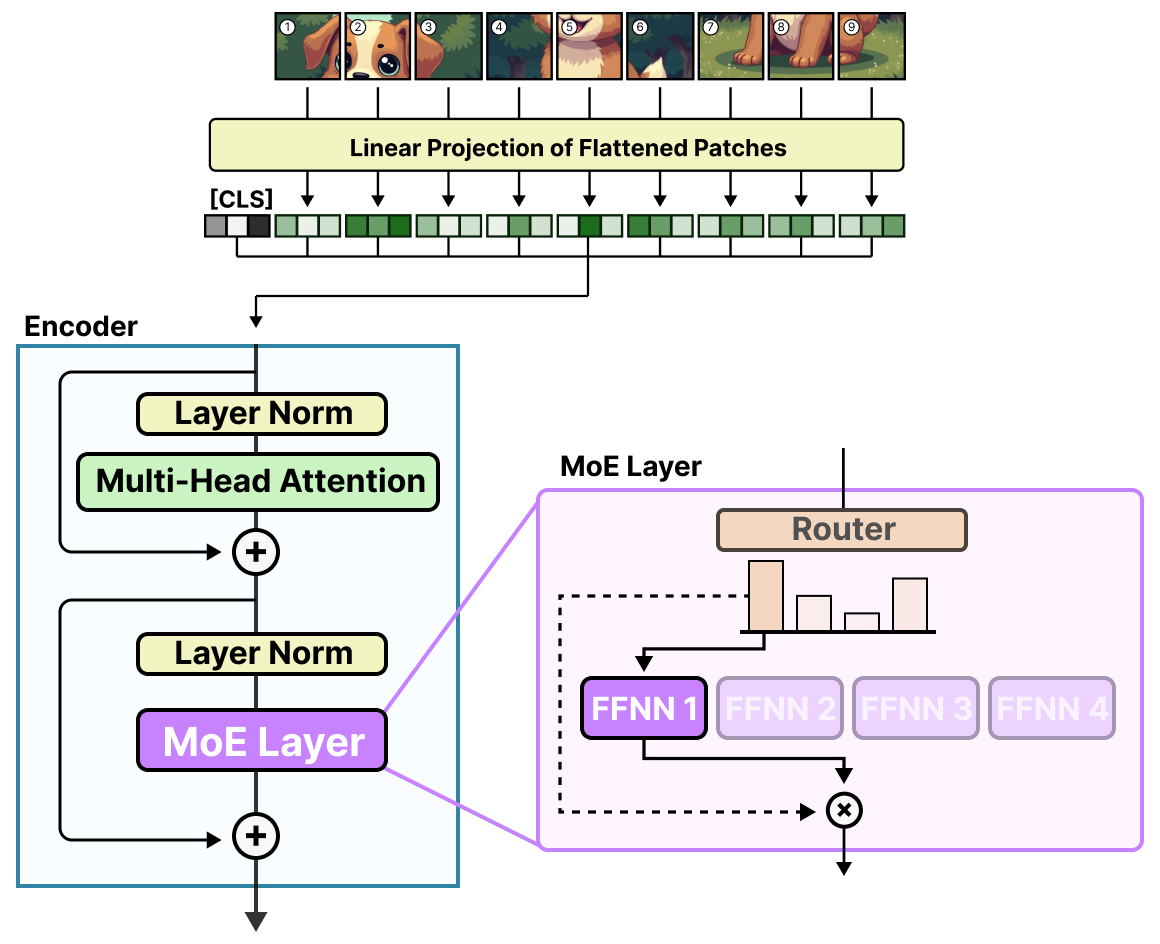
图7: 专家剪枝示意图 (来源: Exploring Language Models)
专家量化
量化将高精度权重转换为低精度表示,显著减少模型大小:
| 方法 | 量化位宽 | 内存减少 | 精度损失 | 推理加速 |
|---|---|---|---|---|
| MC-MoE | 1, 2, 3位 | 4.27x | 3.8% | 1.80x |
| MoE-CSP | 4, 8位 | 4.00x | - | 26.00x |
| MoQE | 2, 3, 4位 | 4.90x | 0.97% | - |
| QMoE | 1, 2位 | 20x | 6.7% | 0.95x |
| CMoE | 1, 2, 4位 | 150x | 23.81% | - |
专家蒸馏与分解
LLaVA-MoD: 使用模仿蒸馏和偏好蒸馏两个阶段,训练小型多模态语言模型。
OneS: 通过知识聚合和蒸馏,将MoE模型转换为密集模型。
MPOE: 采用矩阵乘积算子分解专家权重矩阵。
MoE-I²: 基于专家重要性分配不同的秩进行低秩分解。
3.2 系统级优化
3.2.1 专家并行
专家并行是部署大型MoE模型的关键技术,通过在多设备间分布专家实现分布式执行:

图8: 专家并行示意图 (来源: Microsoft Research)
关键优化方向包括:
Tutel: 动态切换并行策略,使用单一分布布局包含所有最优策略。
Alpa: 重新分类传统并行方法,自动推导高效并行执行计划。
Prophet: 构建负载均衡性能模型,使用贪婪搜索算法找到均衡的专家放置方案。
FlexMoE: 使用细粒度复制策略,选择特定的重量级专家并跨多设备复制。
HetuMoE和DeepSpeed-MoE: 利用分层全对全算法优化通信。
Janus: 采用以数据为中心的方法,在设备间移动专家而非令牌。
ScMoE: 引入短路连接MoE架构,处理当前和前一层的表示。
PipeMoE: 设计性能模型预测计算和通信成本,提出最优多项式时间解决方案。
| 方法 | 加速比 | 基准 | 优化技术 |
|---|---|---|---|
| Lina | 1.63x | DeepSpeed | 优先处理all2all通信 |
| TUTEL | 2.03x | Fairseq | 为权重设计相同布局 |
| ExFlow | 2.2x | Deepspeed-MoE | 将两次all2all操作减少为一次 |
| MoE-Deploy | 3.32x | Tutel | 结合高使用率和低使用率专家 |
| DeepSpeed-MoE | 7.25x | PyTorch | 组合具有相同数据路径的令牌 |
3.2.2 专家卸载
当部署MoE模型到边缘设备时,参数卸载技术是解决GPU内存不足的关键:
专家卸载技术通过将部分专家参数存储在CPU内存或SSD中,仅在需要时将其加载到GPU内存,充分利用MoE模型的稀疏激活特性,显著降低GPU内存需求。
Mixtral-Offloading: 使用当前门控输入预测下一层所需专家,提前加载。
EdgeMoE: 构建预测表,利用当前层专家预测下一层专家。
大多数工作采用LRU策略管理专家缓存,如Mixtral-Offloading和MoE-Deploy。
HOBBIT提出多维缓存策略,结合LRU、LFU和LHU策略。
| 方法 | 加速比 | 基准 | 主要技术 |
|---|---|---|---|
| ProMoE | 1.16x | LRU-MoE | 训练预测器预取专家 |
| Fiddler | 8.20x | MoE-Infinity | 使用CPU辅助计算 |
| HOBBIT | 2.30x | Mixtral-Offloading | 加载自适应精度专家 |
| AdapMoE | 1.36x | Mixtral-Offloading | 动态跳过不重要专家 |
| MoE-Lightning | 3.50x | FlexGen | 调度CPU-GPU-I/O流水线 |
3.3 硬件级优化
随着MoE模型的广泛应用,针对其特性的硬件优化方案不断涌现:
提出近数据处理(NDP)解决方案,整合基于CXL的NDP控制器和专用内核,使用混合计算策略处理"热"和"冷"专家。
首个充分利用FPGA上MoE稀疏性的加速框架,通过M:N剪枝减少计算,通过CEPR执行稀疏激活预测。
首个用于多任务ViT的端到端FPGA实现,提出了GELU函数的近似方法和统一线性层模块。
选择适合每层执行的目标设备,结合xPU和Logic PIM,优化逻辑PIM微架构以优化低Op/B操作。
为移动设备上的SLAM任务提供加速器设计,包括乱序SMoE路由器和异构核心架构。
四、MoE架构的未来发展趋势
4.1 量子加速潜力
量子计算为MoE模型提供了新的加速可能性:

图9: 量子计算与AI结合的概念图 (来源: AI Competence)
量子算法可能为专家选择提供更高效的解决方案,尤其是在处理高维特征空间时。量子搜索算法如Grover算法可以在复杂的专家选择空间中加速搜索过程。
结合量子计算处理特定专家路由决策,而传统硬件执行主要计算任务。这种混合方法可以充分利用量子计算的优势,同时避开其局限性。
利用量子叠加态并行评估多个专家,可能在理论上提供指数级加速。量子叠加允许同时考虑多个专家的输出,从而实现更高效的综合决策。
开发适应量子硬件特性的MoE结构,如利用量子纠缠优化专家通信。设计特定的量子门控机制可以更自然地适应量子计算范式。
实现挑战: 现实中的量子加速仍面临硬件限制、量子退相干、以及量子-经典接口效率等挑战,需要进一步的研究突破。
4.2 边缘计算协同
边缘计算与MoE结合创造了新的部署范式:
将模型分布在端设备和云服务器之间,实现计算资源的最优分配。如MoE2通过协同推理和优化资源分配,高效部署边缘场景中的大语言模型。
将专家分布在不同边缘节点,建立"神经边缘"网络,实现协作计算。这种方法可以充分利用物联网环境中分散的计算资源。
根据边缘设备资源状况动态调整专家分配和激活策略,如AdapMoE框架。这种方法能够适应不同设备和网络条件的变化。
开发针对边缘设备的专用MoE加速硬件,如Edge-MoE和HOBBIT。这些硬件可以高效执行MoE特有的计算模式。
这些技术可能使复杂的AI模型在资源受限的设备上高效运行,为物联网、移动设备和嵌入式系统带来更强大的AI能力。
4.3 算法与架构创新
未来MoE发展还将出现多种创新方向:
专家网络结构可动态变化,适应不同任务需求。这种架构能够通过元学习或神经架构搜索自动调整专家结构。
不同模态数据由专门的专家处理,通过统一路由机制实现信息整合。这种方法可以更自然地处理文本、图像、视频等多种数据类型。
通过动态添加或更新专家,实现模型持续进化而无需完全重训练。这种方法可以高效地适应新知识和新任务。
增强专家选择的透明度和可解释性,使系统决策过程更加清晰。这对于关键应用中的信任和审计至关重要。
结论
混合专家模型(MoE)作为一种强大的架构范式,通过将模型容量与计算效率巧妙平衡,为大规模AI系统开辟了新的可能性。其核心优势在于能够根据输入动态分配计算资源,实现更高效的参数利用。
面对推理优化的挑战,研究者们从模型、系统和硬件三个层面提出了丰富的解决方案。从高效架构设计、专家路由策略优化到创新的硬件加速技术,MoE模型正变得更加高效、灵活和可扩展。
未来,量子计算技术的应用可能为MoE提供更高级的加速能力,而边缘计算协同方案则有望扩展其应用场景。随着算法和架构的持续创新,MoE将继续发挥其在AI系统中的关键作用,推动大规模AI模型向更高效、更强大的方向发展。
无论是在大型数据中心还是资源受限的边缘设备上,MoE都展现出强大的潜力,成为AI系统设计的重要范式。随着研究的深入和技术的成熟,我们可以期待MoE架构在未来AI领域发挥更加重要的作用,推动AI技术的普及与应用。
参考资料
- Fedus, W., Dean, J., & Zoph, B. (2022). A review of sparse expert models in deep learning. arXiv preprint arXiv:2209.01667
- Jiang, A. Q., et al. (2024). Mixtral of experts. arXiv preprint arXiv:2401.04088
- Dai, D., et al. (2024). DeepSeekMoE: Towards ultimate expert specialization in mixture-of-experts language models. arXiv preprint arXiv:2401.06066
- Eliseev, A., & Mazur, D. (2023). Fast inference of mixture-of-experts language models with offloading. arXiv preprint arXiv:2312.17238
- Liu, J., et al. (2024). A Survey on Inference Optimization Techniques for Mixture of Experts Models. arXiv preprint arXiv:2412.14219
- Fedus, W., Zoph, B., & Shazeer, N. (2022). Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23(120), 1-39
- Zhou, Y., et al. (2022). Mixture-of-experts with expert choice routing. Advances in Neural Information Processing Systems, 35, 7103-7114
- Zhong, S., et al. (2024). AdapMoE: Adaptive sensitivity-based expert gating and management for efficient MoE inference. arXiv preprint arXiv:2408.10284
- Kim, T., et al. (2024). Monde: Mixture of near-data experts for large-scale sparse models. Proceedings of the 61st ACM/IEEE Design Automation Conference
- Sarkar, R., et al. (2023). Edge-MoE: Memory-efficient multi-task vision transformer architecture with task-level sparsity via mixture-of-experts. 2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD), pp. 01-09